基于Arachni构建自动化黑盒扫描平台
- 11 mins0x01 简介
对于企业来说,构建自动化黑盒扫描平台是企业安全建设中的一个重要环节,自动化扫描能够有效提升效率,在一定程度上减少常规安全问题的发生。
对于大型互联网和土豪公司来说,都会选择招人自研扫描器或直接购买付费产品,但是对于安全资源有限的公司来说,自研或购买付费产品都是不太现实的,那么性价比较高的方式就是选择基于开源扫描器构建自动化扫描平台。
那么问题来了,目前开源的扫描器有好几种,如何选择一个适合的呢?
首先简单说一说我司情况,主要为APP接口和H5页面,扫描的前端展示自己写,然后调用引擎的API进行扫描,获取结果存储在数据库。
扫描需求包括:
- 主动扫描: 用户可以在界面上手工填写配置(url,cookie,自动登录等),提交扫描任务
- 被动扫描: 通过设置代理的方式,收集测试和预发环境下的请求信息,然后定时扫描
公司之前使用 W3AF 作为黑盒扫描的引擎,总体使用起来效果不是太好,首先其 API 不完全是 REST 风格的,且不支持单接口 POST 扫描(给定请求参数进行扫描)等,所以决定更换一个扫描引擎。
对市面上的开源扫描器简单研究了下,主要从以下几个方面评估:
- 扫描准确率
- 性能
- 支持的扫描漏洞类型
- 爬取页面时,能够模拟用户交互,即是否支持DOM,AJAX等技术
- 支持指定请求参数进行 GET / POST 扫描
- 是否提供 API,且易于使用
- 是否支持登录扫描(带
Cookie或 自动登录) - 部署是否方便,文档是否完善,扫描报告内容是否易于判断误报
- 社区是否活跃,技术支持是否有保证
- …
列的要求比较多,评估的时候尽可能满足就好…
这里根据试用结果和网上资料,对照要求给出结论:
- 准确率:因为时间有限,没有一一测试,参考的的是 sectool的报告,按照表中的结果,Arachni 排在前几位
- 性能:时间原因,没有一一测试
- 漏洞类型: Arachni 对于常见的漏洞类型基本都覆盖到了,完整的类型可以参考 checks
- 模拟用户交互: Arachni 内置 PhantomJS
- 带参数扫描:Arachni 能够通过 vector feed plugin 来支持,支持
GET和POST - API: Arachni 基于 ruby 语言编写,提供了完整的 REST API
- 登录扫描:支持设置
cookie参数,并支持 autologin plugin 来实现自动登录 -
Arachni 提供自包含 package,无需安装依赖;wiki 写的比较详细;报告内容总体还算比较详细,支持多种格式,如
html,json等 - Arachni 代码目前还在更新中,之前在 github 上提 issue,作者都会积极回答,回复速度也比较快,技术支持比较有保障
- …
所以,最后就决定使用 Arachni 了。
在使用 Arachni 的过程中,遇到过一些坑,这里给大家分享一下这段时间使用的一些经验,比如常用场景的配置、注意事项、二次开发等等,希望对大家有帮助~
0x02 部署
在部署方面,Arachni 提供了 self-contained 的 package,所以只需要下载后解压就可以运行了,非常方便,下载地址 稳定版,开发版本,推荐先使用稳定版本
平台支持 Linux, MacOS, Windows,以 linux 为例,下载解压后,运行 rest api server
#./bin/Arachni_rest_server --address 0.0.0.0 --port 8888
Arachni - Web APPlication Security Scanner Framework v2.0dev
Author: Tasos "Zapotek" Laskos <tasos.laskos@Arachni-scanner.com>
(With the support of the community and the Arachni Team.)
Website: http://Arachni-scanner.com
Documentation: http://Arachni-scanner.com/wiki
[*] Listening on http://0.0.0.0:8888
0x03 配置
这里先大致介绍一下 Arachni Rest API 创建扫描任务的配置项,完整的参数和说明可以对照命令行参数说明:
{
"url" : null, // 扫描链接,必须
"checks" : ["sql*", "xss*", "csrf"], // 必须,扫描的漏洞类型,支持通配符 * ,和反选 -xss*,即不扫描所有类型的 xss
"http" : { // http请求相关配置,比如设置 cookie 和 header
"user_agent" : "Arachni/v2.0dev",
"request_headers" : {},
"cookie_string" : {} // 请求中的完整 cookie 字段
},
"audit" : { // 扫描相关配置,比如哪些参数需要扫描,是否要对 cookie,json 进行扫描等
"exclude_vector_patterns" : [],
"include_vector_patterns" : [],
"forms": true, // 扫描 表单
"cookies": true, // 扫描 cookies
"headers": true, // 扫描 headers
},
"input" : { // 设置请求参数的值
"values" : {}
},
"scope" : { // 扫描范围相关,比如限制爬取页面数,限制扫描url路径
"page_limit" : 5,
"path_exclude_pattern" : []
},
"session" : {}, // 登录会话管理,如当前会话有效性验证
"plugins" : {} // 插件,比如设置自动登录,指定请求参数进行扫描
}
接下来以 DVWA 1.9 为测试目标,介绍一些常见场景的扫描配置,DVWA 1.9 的安装和使用大家可以网上搜一下,这里就不做介绍了。
因为 DVWA 1.9 默认登录后返回的 security 级别为 impossible,会导致使用自动登录插件后无法扫出漏洞,这里修改了代码,让它默认返回 low
修改 config/config.inc.php
# Default value for the secuirty level with each session.
# $_DVWA[ 'default_security_level' ] = 'impossible';
$_DVWA[ 'default_security_level' ] = 'low';
场景: 带cookie扫描
配置如下:
{
"url": "http://192.168.1.129/dvwa/vulnerabilities/csrf/",
"checks": [
"csrf" // 只扫描 csrf
],
"audit": { // 只扫描表单字段
"forms": true,
"cookies": false,
"headers": false
},
"scope": {
"page_limit": 4, // 限制爬虫数
"exclude_path_patterns": [ // 不扫描的页面
"logout",
"security",
"login",
"setup"
]
},
"http": {
"cookie_string": "security=low; path=/, PHPSESSID=6oes10c6fem520jid06tv40i16; path=/"
}
}
扫描说明:
checks:仅扫描 csrf
audit:扫描 form 表单,但不扫描 cookie 和 header
scope:限制爬取页面数为 4,不扫描 logout 等会导致 cookie 失效的页面
http: 设置请求的 cookie,这里需要注意的是,每个 cookie 项后都有一个 path 属性,指定作用域。因为如果不指定,cookie 的作用域就是 url 中的 path,比如这里为 /dvwa/vulnerabilities/csrf/,这个时候如果在爬取过程中,爬取到其父路径,请求就不会带上 cookie,导致 server 返回 set-cookie 响应头,覆盖原有 cookie,导致会话失效,所以这里最好设置成根目录 /。
场景: 自动登录扫描
配置如下:
{
"url": "http://192.168.1.129/dvwa/vulnerabilities/sqli/",
"checks": [
"sql_injection"
],
"audit": {
"forms": true,
"cookies": false,
"headers": false
},
"scope": {
"page_limit": 5,
"exclude_path_patterns": [
"logout",
"security",
"login",
"setup"
]
},
"plugins": {
"autologin": {
"url": "http://192.168.1.129/dvwa/login.php",
"parameters": "username=admin&password=password&Login=Login",
"check": "PHPIDS"
}
},
"session": {
"check_url": "http://192.168.1.129/dvwa/index.php",
"check_pattern": "PHPIDS"
}
}
扫描说明:
checks:仅扫描 sql_injection
audit:扫描 form 表单,但不扫描 cookie 和 header
scope:限制爬取页面数为 5,不扫描 logout 等会导致 cookie 失效的页面
plugins & session:使用自动登录插件,url 为登录入口,parameters 为登录需要的参数,格式为 query_sting,通过响应中是否包含 check 的内容来来判断是否登录成功,因为 DVWA 登录成功后返回的是302跳转,响应body为空,导致check失败,此时可以通过配置 session 下的 check_url 和 check_pattern 来实现(引擎会优先使用 session 下的配置),这里检查 index 页面为是否包含 PHPIDS 来判断是否登录成功
场景:指定请求参数对接口进行扫描
当通过设置代理的方式收集到请求信息后, 需要根据请求中的参数来扫描,请求分为 GET 和 POST
POST
Arachni 提供了 vector feed plugin,比如在 DVWA 中,Command Injection 的请求方法是 POST
POST http://192.168.1.129/dvwa/vulnerabilities/exec/
ip=123&Submit=Submit
配置如下:
{
"url": "http://192.168.1.129/dvwa/vulnerabilities/exec/",
"checks": [
"os_cmd_injection*"
],
"audit": {
"forms": true,
"headers": false,
"cookies": false,
"jsons": true,
"ui_forms": true,
"links": true,
"xmls": true,
"ui_inputs": true
},
"http": {
"cookie_string": "security=low; path=/, PHPSESSID=nrd253e2fkqlq8celpkfj9vmn4; path=/"
},
"scope": {
"page_limit": 0
},
"plugins": {
"vector_feed": {
"yaml_string": "type: form\nmethod: post\naction: http://192.168.1.129/dvwa/vulnerabilities/exec/\ninputs:\n ip: 123\n Submit: Submit\n"
}
}
}
扫描说明:
checks:仅扫描 os_cmd_injection
audit:扫描 form 表单,但不扫描 cookie 和 header
http: 设置请求的 cookie_string
scope:这里 page_limit 需要设置为 0,如果设置为 1 ,则不会进行扫描
plugins :使用 vector_feed 插件,参数为 yaml_string ,即符合 YAML 语法的字符串。这里解释一下如何生成这个值
首先把字符串在 python 命令中打印出来
>>> print "type: form\nmethod: post\naction: http://192.168.1.129/dvwa/vulnerabilities/exec/\ninputs:\n ip: 123\n Submit: Submit\n"
type: form
method: post
action: http://192.168.1.129/dvwa/vulnerabilities/exec/
inputs:
ip: 123
Submit: Submit
对应字段如下:
action: 请求的url
method: 请求方法为 post
type: 请求body的类型,这里为表单所以为 form,如果body是 json 的话,这里需要设置为 json
inputs: 请求的参数,这里有两个参数 ip 和 Submit
在 YAML 缩进是很重要的,对于 type 为 json 时,因为 值可能会为一个object,比如
{
"key1": "value1",
"key2": {
"key3": "value3"
}
}
那么生成的 YAML 就为:
key1: value1
key2:
key3: value3
可以看到 key3 前面有空格。
这个转换过程可以使用 YAML 库来进行转换,比如在 python 中可以使用 pyyaml 库的 yaml.safe_dump 方法,将 dict 转为 yaml string:
post_body['plugins'] = {
"vector_feed": {
# http://pyyaml.org/wiki/PyYAMLDocumentation
"yaml_string": yaml.safe_dump(yaml_json, default_flow_style=False)
}
}
GET
对于 GET 的请求,请求参数是在 url 的 query string 中的,可以直接设置 url 属性,此时 page_limit 需要设置成 1。
因为 page_limit 的值在使用和不适用插件时的含义有所不同,这里为了避免这个问题,对于 GET 也推荐使用 vector_feed 来配置
这里以 DVWA 的 sql注入为例
配置如下:
{
"url": "http://192.168.1.129/dvwa/vulnerabilities/sqli/?id=111&Submit=Submit#",
"checks": [
"sql_injection"
],
"audit": {
"headers": false,
"cookies": false,
"links": true
},
"http": {
"cookie_string": "security=low; path=/, PHPSESSID=nrd253e2fkqlq8celpkfj9vmn4; path=/"
},
"scope": {
"page_limit": 0
},
"plugins": {
"vector_feed": {
"yaml_string": "action: http://192.168.1.129/dvwa/vulnerabilities/sqli/\ninputs:\n id: 1\n Submit: Submit\n"
}
}
}
扫描说明:
checks:仅扫描 sql_injection
audit:因为是 GET ,所以这里设置扫描 links ,但不扫描 cookie 和 header
http: 设置请求的 cookie
scope:这里 page_limit 需要设置为 0,如果设置为 1 ,则不会进行扫描
plugins :使用 vector_feed 插件,参数为 yaml_string ,即符合 YAML 语法的字符串。GET 的情况需要的参数少一些
>>> print "action: http://192.168.1.129/dvwa/vulnerabilities/sqli/\ninputs:\n id: 111\n Submit: Submit\n"
action: http://192.168.1.129/dvwa/vulnerabilities/sqli/
inputs:
id: 111
Submit: Submit
只需要设置 action 和 inputs 即可
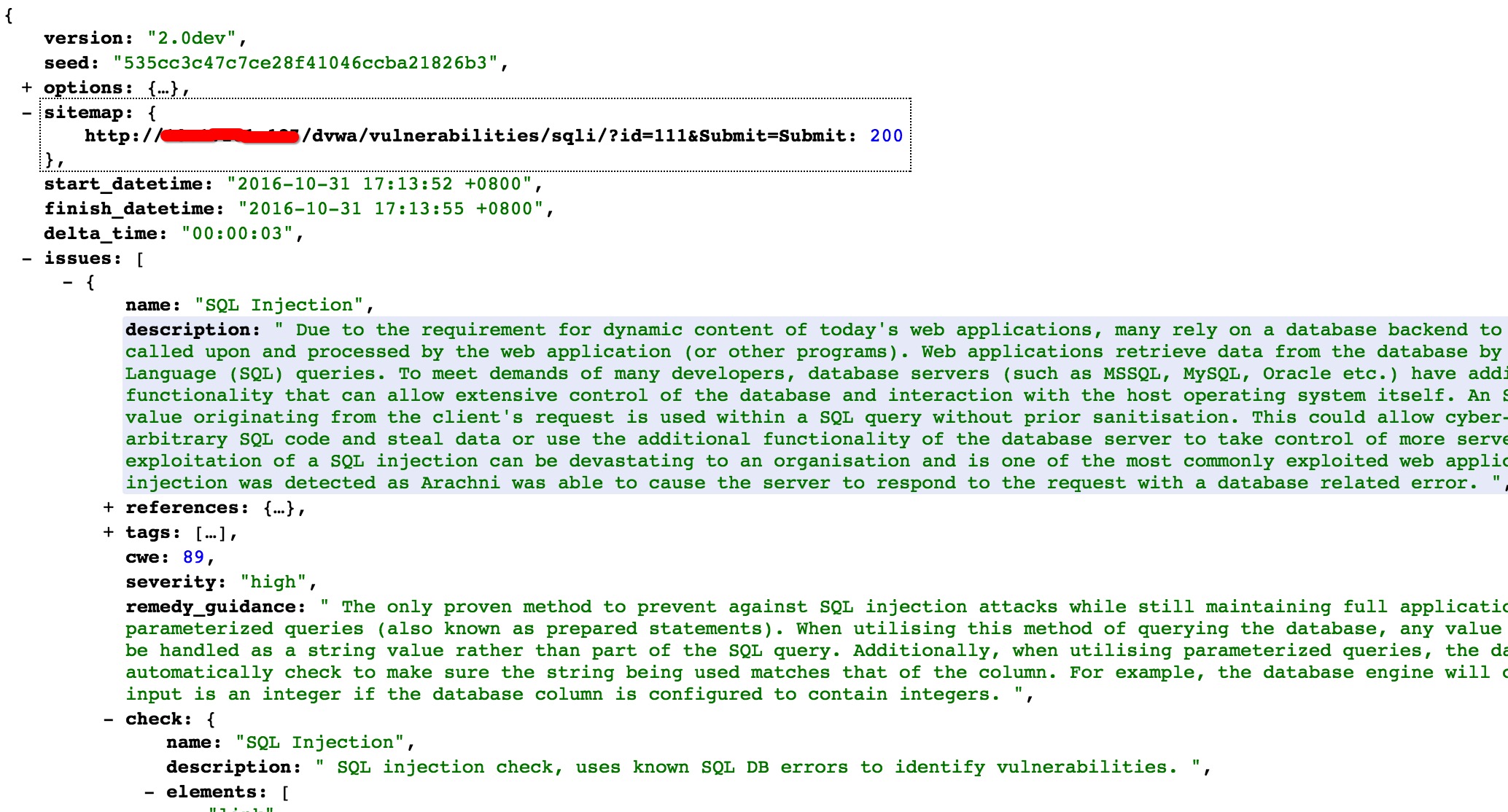
扫描报告
对于查看扫描进度,暂停,删除扫描的 API 都比较简单,这里就不详细介绍了。
扫描完成后,可以通过如下 API 来获取指定格式的报告,支持多种格式
GET /scans/:id/report
GET /scans/:id/report.json
GET /scans/:id/report.xml
GET /scans/:id/report.yaml
GET /scans/:id/report.html.zip
扫出的问题在响应的 issues 部分
0x04 二次开发 & 打包
如果在使用过程中遇到bug和误报,想进行调试或修改,可以自己搭建开发环境进行调试和修改
开发环境设置
参考 wiki 的 Installation#Source based
需要装以下依赖
- Ruby 2.2.0 up to 2.3.3.
- libcurl with OpenSSL support.
- C/C++ compilers and GNU make in order to build the necessary extensions.
- PhantomJS 2.1.1
然后执行
git clone git://github.com/Arachni/arachni.git
cd arachni
# 替换成国内源
gem sources --add https://gems.ruby-china.org/ --remove https://rubygems.org/
gem install bundler # Use sudo if you get permission errors.
bundle install --without prof # To resolve possible dev dependencies.
启动
./bin/Arachni_rest_server --address 0.0.0.0 --port 8888
直接修改代码,然后创建扫描任务就可以进行测试,日志在 logs 目录下
打包
参考 [Development-environment][10] ,这里说下我的步骤
把以下三个依赖的项目拉到公司的 gitlab
需要修改的地方有以下几个地方
-
修改 arachni-ui-web 的Gemfile,将以下部分
gem 'arachni' , '~> 1.5'替换成 gitlab 的地址,推荐用 ssh
gem 'arachni', :git => 'ssh://xxxxxxxx/arachni.git', :branch => 'master' -
修改 build-scripts 的 lib/setenv.sh ,将以下部分
export ARACHNI_BUILD_BRANCH="experimental" export ARACHNI_TARBALL_URL="https://github.com/Arachni/arachni-ui-web/archive/$ARACHNI_BUILD_BRANCH.tar.gz"修改成 gitlab arachni-ui-web 的仓库分支 和 代码下载地址
# gitlab 仓库分支 export ARACHNI_BUILD_BRANCH="master" # gitlab arachni-ui-web 的代码下载地址,需要为 tar.gz export ARACHNI_TARBALL_URL="http://xxxxxxxx/arachni-ui-web/repository/archive.tar.gz?ref=master" -
运行打包命令
bash build_and_package.sh如果下载依赖过程中,遇到网速问题,可以配合 proxychains 。这里说一下,脚本执行过程中中断,再次运行会从上次中断的地方开始,因为打包过程需要从内网 gitlab 拉代码,所以记得下载依赖包后,停止,去掉 proxychains,然后再运行
0x05 总结
因为 Arachni 提供的参数较多,文中只针对常见和比较重要的部分进行了分析和介绍,希望能在构建自动化黑盒扫描平台时,给大家提供一些参考。
另外,如果哪里有写的不对或者不准确的地方,也欢迎大家指出。
0x06 参考
